
Operations Management System Oil and Gas: 2026 Mastery
Master your operations management system oil and gas. Get a no-nonsense guide to what it is, why it matters, and how to empower your frontline teams in 2026.
Dan Robin

The call usually comes when the site is dark, the office is empty, and nobody has time for theory. A valve was isolated wrong. A permit wasn't updated across the shift handover. A contractor followed an old instruction because that was the version sitting in the trailer.
That's the moment an operations management system stops being a corporate phrase and becomes something much simpler. A way to keep people aligned when the pressure is on.
It Starts with a Call in the Middle of the Night
You pick up half awake, already trying to piece the job together from fragments. Which crew was on. What changed since yesterday. Whether the latest maintenance note made it to the night shift. If you've worked around plants, terminals, pipelines, or offshore crews long enough, you know this feeling. The incident itself might be small. The confusion around it usually isn't.

Most bad nights don't start with one dramatic mistake. They start with drift. A procedure gets updated but the field copy doesn't. One supervisor briefs his crew well, another assumes everyone already knows. A maintenance task gets logged in one system, a safety note lives in another, and the contractor sees neither. On paper, everything exists. In practice, the chain breaks.
The problem usually isn't effort
This is what people outside operations often miss. Teams are rarely careless. They're busy, stretched, and working across shifts, sites, and contractors. If the system asks them to check five places before starting a job, they won't. Not because they don't care. Because the job still has to get done.
Practical rule: If critical information depends on someone remembering where to look, the system is already weak.
That's why a good operations management system in oil and gas matters. Not as a compliance artifact. As a control system for real work. It should tell people what changed, what matters now, who owns the next step, and whether the message landed.
Data problems turn into operating problems
The cost of messy information isn't abstract. One industry source reports that organizations lose an estimated $2 million per year due to poor data management, and 95% of IT leaders say day-to-day data management is challenging, according to EnergySys on successful data management in oil and gas. In this industry, that shows up as downtime, rework, missed context, and delayed decisions.
A lot of managers think they need a better dashboard. Often they need something more basic first. One place where the latest instruction, risk note, and task status meet the person doing the work.
That's what keeps the 3 a.m. phone from ringing in the first place.
Beyond the Binder on the Shelf
For years, operations management meant a binder. Thick, approved, carefully indexed, and mostly disconnected from the shift that had to use it. It looked serious. It satisfied audits. It didn't always help a technician at the far end of the asset make the right call at the right time.
A modern operations management system oil and gas setup is different. It isn't a manual. It's the operating logic of the business. It connects risk, work, controls, learning, and accountability so the operation runs the same way on a quiet Tuesday as it does during an upset.
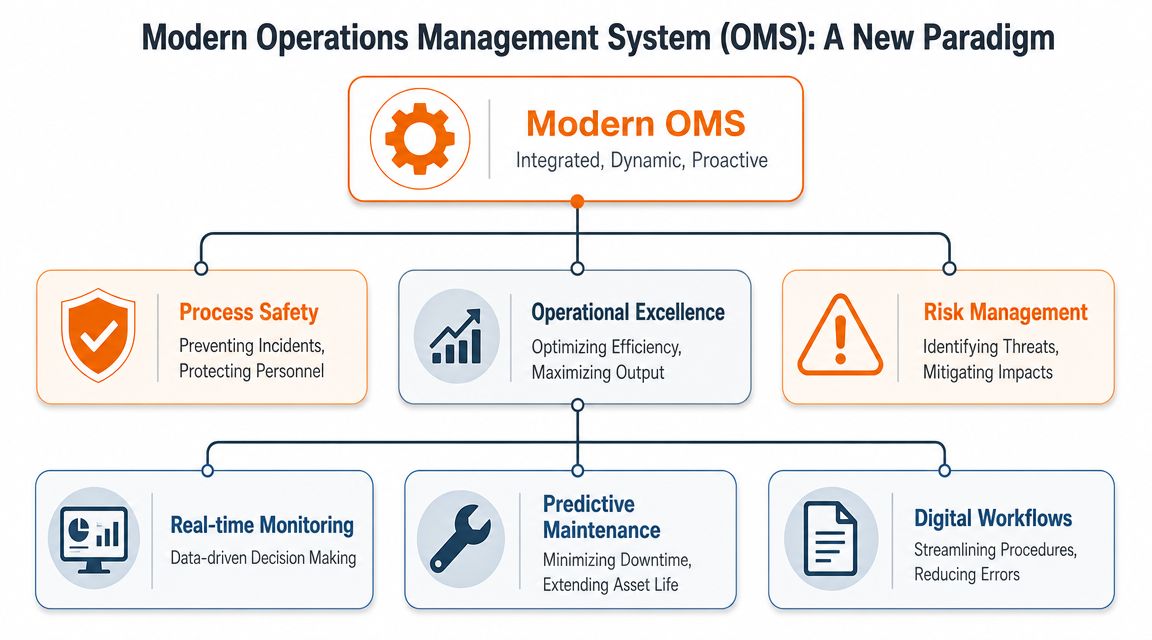
What changed in the modern OMS
The formal framework took shape in the 2010s as the industry pushed for a more consistent way to manage risk and performance across the full asset lifecycle, from construction through decommissioning. IOGP's framework covers occupational health and safety, environmental and social responsibility, process safety, quality, and security, and it uses a Define–Do–Check–Act loop to build learning back into operations, as outlined by Ipieca's overview of the operating management system framework.
That matters because oil and gas doesn't give you the luxury of managing one type of risk at a time. Mechanical integrity, contractor control, environmental exposure, permit discipline, and production pressure all show up together. A real OMS gives those things one shared structure.
If you want a good parallel from outside the sector's language, a business management system manual is useful for understanding how high-level controls become day-to-day operating discipline. The principle is the same. The work only improves when the system is live, current, and used.
It's a loop, not a document
The best way to think about an OMS is simple:
Define the work: Clarify standards, risks, roles, and expected controls.
Do the work: Execute under those controls, not based on memory or habit.
Check the work: Watch what happened, verify what held, and catch what drifted.
Act on the learning: Adjust the system so the next shift starts smarter.
A shelf can store procedures. It can't create discipline, confirm understanding, or push learning back into the next job.
That's the dividing line. A binder preserves information. An OMS moves information through the operation.
And if it doesn't reach the frontline, it isn't an operating system. It's paperwork.
The Five Pillars of a Modern Oil and Gas OMS
Most OMS efforts get fuzzy because people talk about “the system” like it's one thing. It isn't. It's a set of working parts that have to reinforce each other. When one part is weak, the field feels it fast.
I've found it more useful to think in five pillars. Not because the number is magic, but because these are the functions crews keep coming back to when things either work smoothly or start slipping.
Asset and maintenance management
In oil and gas, equipment condition sets the tempo for everything else. If maintenance history is incomplete, if inspection findings sit in a separate folder, or if operators can't see whether a temporary fix is still in place, the OMS is already compromised.
This pillar is about more than scheduling work orders. It's about context. The planner needs to know what has failed before. The supervisor needs to see what can wait and what can't. The technician needs the current procedure, not last year's version with handwritten edits in the margin.
Good maintenance management creates trust in the plant. Bad maintenance management creates workarounds.
Workforce and shift management
A strong OMS respects the handover. It doesn't assume one shift naturally understands what the last shift meant. It makes the transfer of risk explicit.
That includes a few practical disciplines:
Role clarity: People know who is accountable for the task, the permit, and the decision to stop.
Certification visibility: Supervisors can confirm that the person assigned is cleared and current for the job.
Handover quality: Crews get the live status of equipment, isolations, open actions, and exceptions before they inherit the work.
A lot of incidents aren't really “operator error.” They're handover error. The system left too much unsaid.
Safety and compliance
This is the bedrock, but it's where many systems become performative. A site can have strong policies and still leave workers hunting for the right permit condition, the latest alert, or the current control measure.
The point of this pillar is to make compliance usable. Not hidden in forms. Not trapped in a monthly review. Usable on the job, in sequence, when someone needs to decide whether to proceed.
If a control only exists in an audit file, it won't protect anyone in the field.
That means permits, procedures, incident learnings, contractor requirements, and critical risk controls have to show up where the work happens. The OMS should reduce interpretation, not create more of it.
Standardized workflows and procedures
Consistency sounds boring until you've seen what inconsistency costs. Different teams doing the “same” job in three different ways is not flexibility. It's unmanaged variation.
This pillar is where companies often resist discipline because experienced people don't like being boxed in. Fair enough. But standardization doesn't mean treating skilled operators like robots. It means agreeing on the essential elements, then making the workflow easy to follow.
A healthy standard has three qualities:
Workflow quality | What it looks like in practice | Why crews accept it |
|---|---|---|
Clear | The steps are short, current, and written in field language | People can use it without translating office language |
Available | It's accessible on shift, at the site, and during the job | Nobody has to chase the latest version |
Owned | Supervisors and operators help refine it after use | The process reflects reality, not wishful thinking |
Analytics and reporting
This pillar comes last on purpose. Reporting matters, but it should serve operations, not the other way around. Too many OMS programs drown crews in data and still leave managers blind to the core issue.
Useful reporting tells you where execution is drifting. Which work sits open too long. Which sites repeat the same exception. Where messages are acknowledged but not acted on. Which controls are always bypassed because the process doesn't fit the work.
The right analytics don't flatter leadership. They tell the truth early enough to fix something.
Put together, these five pillars create an OMS that people can run. Separate them, and you get the familiar mess of one team handling maintenance, another tracking compliance, another chasing reports, and nobody owning the whole picture.
From Cost Center to Competitive Advantage
A lot of leadership teams still talk about OMS as if it lives in the same bucket as mandatory training and audit prep. Something you fund because you have to. That's a narrow view, and it leaves money on the table.
A well-run OMS improves operations in ways finance can understand. Fewer surprises. Better control of maintenance timing. More reliable execution across shifts. Clearer visibility into where risk is building before it turns into downtime or bad decisions. Those aren't soft benefits. They change how an asset performs.

The business case gets stronger when systems get connected
The conversation around OMS is shifting with predictive maintenance and digital twins. The focus is moving away from static compliance systems and toward connected, data-fed operating systems that reduce unplanned shutdowns, extend equipment life, and strengthen safety through analytics, as described in Akselos' piece on predictive maintenance for oil and gas operations.
That shift matters because old OMS thinking treated maintenance, risk, and operations as neighboring functions. Modern practice works better when those functions share one operating rhythm. A maintenance signal should inform risk decisions. A risk review should change the work plan. A change in asset condition should reach the next shift before the next task starts.
What boards care about
Boards don't want a lecture on framework maturity. They want to know whether the company is easier to run, safer to operate, and less exposed to avoidable disruption. An OMS earns respect when leaders can point to outcomes like:
More predictable operations: Less confusion about current status, open actions, and work ownership.
Better asset stewardship: Maintenance decisions are driven by current operating context, not static intervals alone.
Stronger operational discipline: Procedures and risk controls are used in the field, not just approved centrally.
Cleaner decision-making: Leaders see emerging problems earlier because information is connected.
The strongest OMS programs stop competing with production. They become part of how production stays reliable.
There's also a subtler advantage. Companies with a practical OMS can absorb change better. New contractors, aging assets, changing priorities, and operating upsets don't hit as hard when communication, control, and learning already have a home.
That's why I don't treat OMS as overhead. I treat it as infrastructure. You don't notice it much when it's good. You notice it fast when it's weak.
Where Most Operations Management Systems Fail
Most OMS failures don't happen in the design workshop. They happen later, when a polished framework meets a noisy site and nobody changes the way information moves.
The hard truth is simple. The main failure mode isn't a lack of policy. It's the gap between central intent and frontline execution. That's also the point made in this analysis of connected risk management in oil and gas. Companies know how to write standards. They struggle to keep those standards alive across shifts, remote sites, and contractor networks.
The last mile is where systems break
Head office approves a revised procedure. The plant superintendent sees it. The day supervisor mentions it in a meeting. The night shift gets a partial version during handover. The contractor keeps working from a printed copy issued last month.
Nobody meant to fail. The system failed because it relied on too many relays.
That's why I pay close attention to the last mile. Can the field receive updates fast. Can supervisors confirm who has seen them. Can crews ask questions inside the same flow instead of starting a side conversation on text messages and calls. Can contractors work from the same live instruction set as employees. If not, the OMS is fragile.
A lot of what shows up in broader compliance management systems applies here too. Controls only hold when the people executing them can access, understand, and act on them in the moment.
Common failure patterns
These are the ones I see repeatedly:
Too much abstraction: Policies are written at a level that sounds good but doesn't guide the job.
Split systems: Work orders, safety notes, procedures, and shift updates live in different tools.
Weak handovers: Critical context gets summarized casually instead of transferred deliberately.
Contractor exclusion: Contractors carry real risk exposure but operate outside the communication loop.
No follow-through: Messages are sent, but nobody verifies understanding or action.
A procedure that doesn't reach the person doing the work is no better than a procedure that was never written.
Companies often respond by adding more governance. More reviews. More reports. More gates. That can make the paperwork healthier while making execution worse. The field doesn't need more theory. It needs fewer gaps.
The best fix is usually boring. Shorter information paths. Fewer tools. Clearer ownership. Live updates. And a system that treats communication as a control, not an afterthought.
Choosing Your Tools and Rolling Them Out
Tool selection gets derailed when buyers focus on feature volume instead of operating fit. In this space, the right question isn't “Can it do everything?” It's “Will the frontline use it when the pace is high and the signal matters?”
If a tool adds friction, people route around it. They call, text, screenshot, or fall back on memory. Once that starts, your OMS lives in slides while the actual operation runs somewhere else.
What to look for in a tool
I'd keep the evaluation grounded in a small set of questions. You can use a detailed market guide later, including resources on operations management tools, but the first screen should be practical.
Criteria | Why It Matters | Your Answer (Yes/No) |
|---|---|---|
Built for frontline use | If the interface is awkward on a phone or in the field, adoption drops | |
Unifies communication and work | Teams need updates, tasks, documents, and conversations in one place | |
Handles shift-based operations | Handover, scheduling, and current status must work across crews | |
Supports contractors safely | Contractors need controlled access to the right information | |
Makes version control obvious | Crews must know they are using the latest procedure or notice | |
Confirms receipt and follow-through | Sending information isn't enough. You need to know what happened next | |
Rolls out quickly | Long deployments lose momentum and invite redesign fatigue | |
Fits existing governance | The tool should support your operating model, not force a new one overnight |
Roll out one workflow first
The biggest rollout mistake is the grand launch. New app, new rules, new terminology, new expectations, all at once. It looks ambitious. It usually lands badly.
Start with one workflow that people already feel pain from. Shift handover is a common candidate. Permit updates can work too. Maintenance coordination across operations and contractors is another strong place to start. Pick the flow where delays, ambiguity, or stale information already create friction everyone recognizes.
Then keep the rollout plain:
Map the current path so you can see where information gets lost.
Strip the workflow down to the minimum fields and actions needed to run it well.
Pilot with one crew or site that has a supervisor willing to tell the truth.
Adjust fast based on actual use, not what the project team hoped would happen.
Expand only after crews trust it enough to prefer it over old workarounds.
Adoption is earned on the ground
You don't win adoption with a memo. You win it when the tool saves a supervisor time, prevents a missed handover point, or helps a technician get the right document without chasing three people.
Ask one blunt question during the pilot: “Did this make the job easier today?” If the answer is no, keep fixing.
That's the standard. Not whether the project closed on schedule. Whether the people carrying the risk think the tool helps them do the work.
An OMS Is About People Not Just Processes
The best OMS I've seen didn't feel heavy. People weren't constantly talking about the framework. They just knew where to find the current instruction, how to hand work over cleanly, who owned the next action, and what to do when conditions changed.
That is the core idea. An operations management system in oil and gas isn't there to worship process. It's there to give people enough clarity and connection to manage risk well under real operating pressure.
What good looks like day to day
You can usually tell when the system is healthy:
Crews trust the information because it's current and easy to access.
Supervisors spend less time chasing context and more time coaching the work.
Contractors aren't operating in the dark or outside the communication chain.
Lessons don't die in reports because they come back into daily execution.
When those habits take hold, the OMS fades into the background. That's a good thing. It means the operation has stopped treating discipline as a special event.
And yes, it means you sleep a little better. Not because risk disappears. It never does. But because the system respects the people closest to it.
If your teams are spread across sites, shifts, and job types, a tool like Pebb is worth a look. It brings communication, tasks, documents, scheduling, and frontline coordination into one place, which is exactly where many OMS efforts either come together or fall apart.
